Tutorial on the Calculation of Tight-Binding Parameters
This notebook provides a guide to the use of the Linear Combination of Atomic Orbitals (LCAO) method as implemented in the QuantumDNA package. The LCAO approach, as parameterized by Mantela et al., provides an efficient representation of the electronic properties of DNA molecules based on their atomic configurations.
The primary input to this method is the atomic geometry of the bases that make up the DNA molecule. These geometries can be obtained from various databases and modeling tools. In this notebook, we present three practical examples that demonstrate how to use QuantumDNA with geometries derived from different sources:
Examples in this notebook:
Example I: 1BNA Dodecamer. Demonstrates the integration of DNA atomic geometries from the Protein Data Bank (PDB), focusing on the well-known 1BNA dodecamer structure.
Example II: Biovia Discovery Studio Geometries Explores how geometries generated with Biovia Discovery Studio can be seamlessly integrated into the LCAO workflow.
Example III: PubChem Nucleobase Geometries Demonstrates the use of geometries obtained directly from PubChem, highlighting the flexibility of QuantumDNA in handling nucleobase-level data.
By the end of this notebook, you will have a clear understanding of how to import, process, and use atomic geometries for DNA molecules from different sources, unlocking the full potential of the QuantumDNA package for your research.
![]()
[1]:
%load_ext autoreload
%autoreload 2
# Save flag: Set to True to enable saving results (currently unused in this script)
save = False
# Verbose flag: Set to True to enable detailed logging
verbose = False
Setup
[2]:
import numpy as np
import matplotlib.pyplot as plt
# --------------------------
# Installation of QuantumDNA
# --------------------------
from importlib.util import find_spec
qDNA_installed = find_spec('qDNA') is not None
if not qDNA_installed:
%pip install qDNA
print("Successfully installed the 'qDNA' package.")
else:
print("Package 'qDNA' is already installed.")
if verbose:
%pip show qDNA
from qDNA import *
# ------------------------
# Directory Setup
# ------------------------
import os
DATA_DIR_QDNA = DATA_DIR
# Use the current working directory as the root
ROOT_DIR = os.getcwd()
# Define directories to load data
DATA_DIR = os.path.join(ROOT_DIR, "data")
os.makedirs(DATA_DIR, exist_ok=True)
# Define directory to save figures
SAVE_DIR = os.path.join(DATA_DIR, "my_figures")
os.makedirs(SAVE_DIR, exist_ok=True)
# Define the directory to load figures
FIG_DIR = os.path.join(DATA_DIR_QDNA, "raw", "figures_tutorials")
if verbose:
print(f"Data directory: '{DATA_DIR}' is ready.")
print(f"Save directory: '{SAVE_DIR}' is ready.")
print(f"Figures directory: '{FIG_DIR}' is ready.")
Package 'qDNA' is already installed.
Example I: 1BNA Dodecamer
The RCSB Protein Data Bank (PDB) is a globally recognized, open-access repository that archives three-dimensional structural data of biological macromolecules, including proteins and nucleic acids. This resource is indispensable across various scientific disciplines, such as molecular biology, computational biology, and structural bioinformatics, facilitating advancements in research and education.
In this tutorial, we will utilize the 1BNA structure, which represents a B-form DNA dodecamer with the sequence 5'-D(*CP*GP*CP*GP*AP*AP*TP*TP*CP*GP*CP*G)-3'. This synthetic DNA fragment has been extensively studied to understand DNA conformation, base pairing, and interactions with various molecules, including proteins and drugs. The high-resolution crystal structure of 1BNA, determined at 1.9 Å, reveals a right-handed double-stranded B helix, serving as a foundational model for DNA
structural analysis.
By integrating the 1BNA structure from the RCSB PDB into our QuantumDNA package, we can effectively demonstrate the application of the Linear Combination of Atomic Orbitals (LCAO) method in analyzing DNA molecules. To prepare this structure for simulations and analysis, we will follow these steps:
.pdb format.data/my_geometries).2. Prepare the Structure Use Biovia Visual Studio (or any molecular modeling tool of your choice) to refine the structure: Remove the sugar-phosphate backbone and water molecules, include hydrogen atoms and save the modified structure in .pdb format.
3. Run the Code Below Apply the following Python code to process the modified .pdb file.
[3]:
filename = '1BNA1'
filepath_pdb = os.path.join(DATA_DIR, "my_geometries", "RCSB", f"{filename}.pdb")
oligo = Oligomer(filepath_pdb)
oligo.save_tb_params()
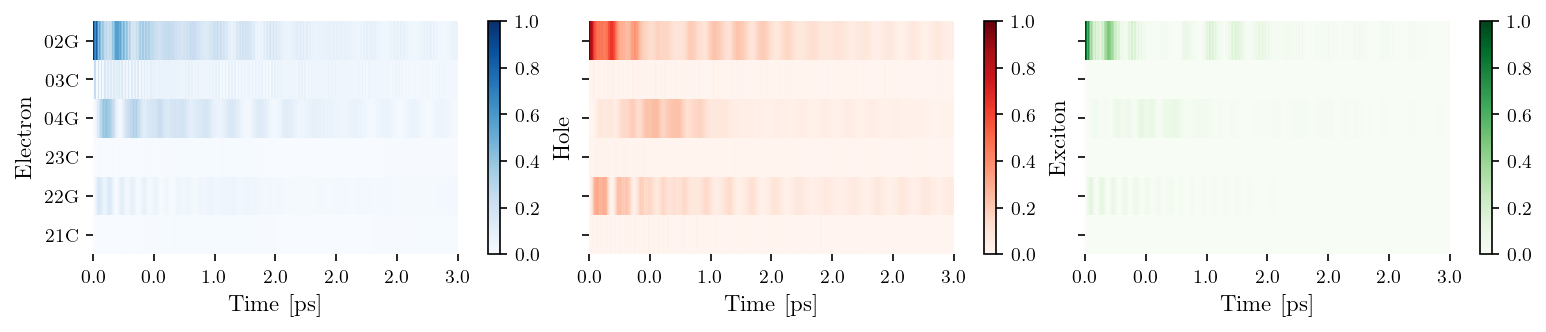
tb_sites = [['02G', '03C', '04G'], ['23C', '22G', '21C']]
vis = Visualization(tb_sites, relax_rate=3., source = filename)
fig, ax = vis.plot_heatmap()
if save:
fig_filename = input("Filename for Saving: ")
plt.savefig(os.path.join(SAVE_DIR, fig_filename + '.pdf'))
[4]:
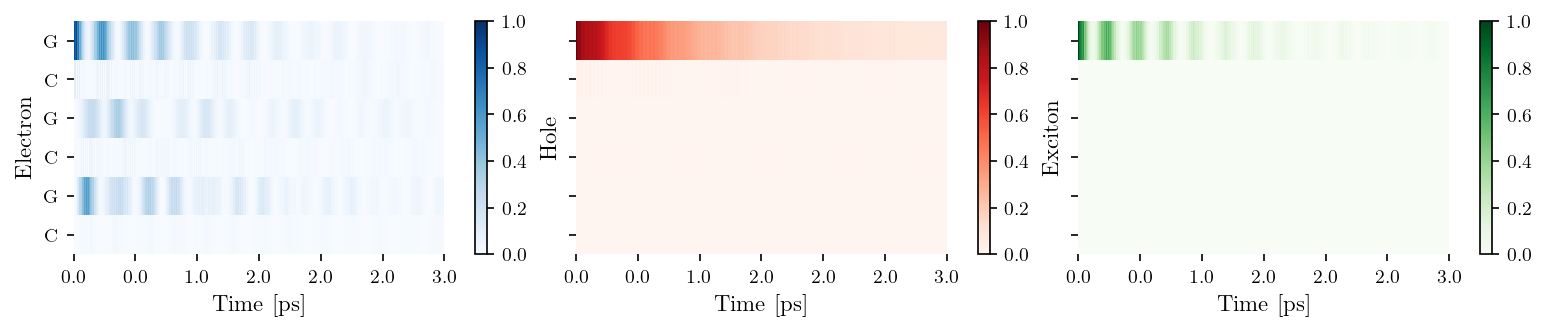
tb_sites = [['G', 'C', 'G'], ['C', 'G', 'C']]
vis = Visualization(tb_sites, relax_rate=3., source = "Hawke2010")
fig, ax = vis.plot_heatmap()
if save:
fig_filename = input("Filename for Saving: ")
plt.savefig(os.path.join(SAVE_DIR, fig_filename + '.pdf'))
Example II: Geometries from Biovia Discovery Studio
Using Biovia Discovery Studio or similar molecular editing software, you can generate PDB files of DNA and RNA sequences with optimized geometries. These tools offer flexibility to model nucleic acid structures with a high degree of customization. For example, you can:
introduce single-base mismatches,
apply epigenetic modifications such as methylation
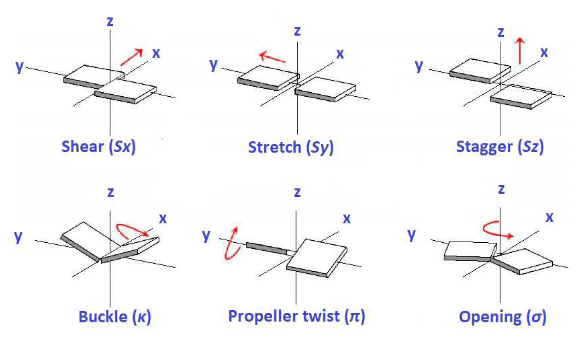
perform translations or rotations of individual bases relative to one another (see the illustration below)
These modifications allow for in-depth investigations into how structural variations impact the electronic properties of nucleic acids.
One of the most common base mismatches observed in DNA is the G·T mismatch, which occurs when guanine pairs with thymine instead of its usual partner, cytosine. As an example, we will examine the G·T mismatch resulting from such a mutation, along with cytosine methylation in the sequence ATGAC. This configuration allows us to investigate how a single mismatch, combined with an epigenetic modification, can influence the electronic properties and structural integrity of DNA.
When preparing geometries for use with the QuantumDNA package, it is important to ensure that the sugar-phosphate backbone and any water molecules are removed in Biovia Discovery Studio or your chosen software. This preprocessing step is essential for focusing solely on the atomic configurations of the bases and their interactions.
[5]:
from IPython.display import Image
citation = "M. Mantela, C. Simserides and R. Di Felice, LCAO electronic structure of nucleic acid bases and other heterocycles and transfer integrals in B-DNA, including structural variability. *Materials 14*, 4930 (2021)"
print(f"Image taken from: {citation}.")
Image(filename=os.path.join(FIG_DIR,'base_translation_rotation.png'), width=600)
Image taken from: M. Mantela, C. Simserides and R. Di Felice, LCAO electronic structure of nucleic acid bases and other heterocycles and transfer integrals in B-DNA, including structural variability. *Materials 14*, 4930 (2021).
[5]:
[6]:
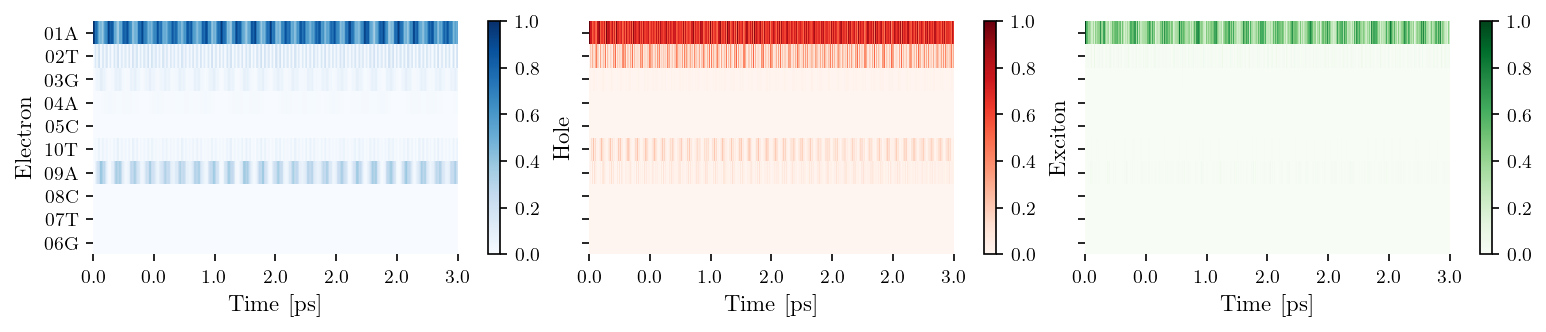
filename = "wildtype_ATGAC"
filepath_pdb = os.path.join(DATA_DIR, "my_geometries", "Biovia", f"{filename}.pdb")
oligo = Oligomer(filepath_pdb, lower_continued=False)
oligo.save_tb_params()
tb_sites = [['01A', '02T', '03G', '04A', '05C'], ['10T', '09A', '08C', '07T', '06G']]
vis = Visualization(tb_sites, relaxation=False, source = filename)
fig, ax = vis.plot_heatmap()
if save:
fig_filename = input("Filename for Saving: ")
plt.savefig(os.path.join(SAVE_DIR, fig_filename + '.pdf'))
[7]:
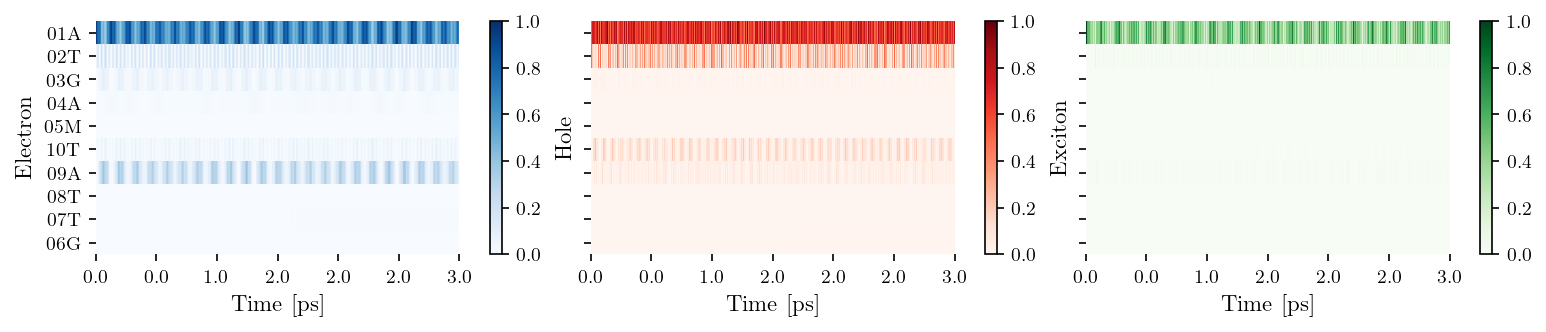
filename = "modified_ATGAC"
filepath_pdb = os.path.join(DATA_DIR, "my_geometries", "Biovia", f"{filename}.pdb")
oligo = Oligomer(filepath_pdb, lower_continued=False)
oligo.save_tb_params()
tb_sites = [['01A', '02T', '03G', '04A', '05M'], ['10T', '09A', '08T', '07T', '06G']]
vis = Visualization(tb_sites, relaxation=False, source = filename)
fig, ax = vis.plot_heatmap()
if save:
fig_filename = input("Filename for Saving: ")
plt.savefig(os.path.join(SAVE_DIR, fig_filename + '.pdf'))
Example III: Pubchem Nucleobase Geometries
To perform simulations at the nucleobase level with high accuracy, you can utilize geometries sourced from PubChem, a comprehensive database for small molecules and biological macromolecules. By downloading the molecular structure in the JSON file format from PubChem, you gain access to well-optimized geometries suitable for quantum mechanical simulations.
In this example, we demonstrate how to leverage these geometries to calculate several important quantum properties, including:
HOMO and LUMO Energies The highest occupied molecular orbital (HOMO) and the lowest unoccupied molecular orbital (LUMO) energies are critical for understanding the electronic structure of a molecule. These values are directly related to the molecule’s chemical reactivity, stability, and ability to participate in charge transfer processes.
Higher and Lower Molecular Orbitals Beyond the HOMO and LUMO, analyzing higher and lower molecular orbitals provides a more complete picture of the molecule’s electronic structure and the distribution of electronic density.
Dipole Moment The dipole moment quantifies the separation of positive and negative charges within the molecule, reflecting its polarity. This property is crucial for understanding intermolecular interactions, such as hydrogen bonding and van der Waals forces.
Oscillator Strength The oscillator strength measures the intensity of electronic transitions between energy levels, which is essential for predicting absorption spectra and understanding light-matter interactions.
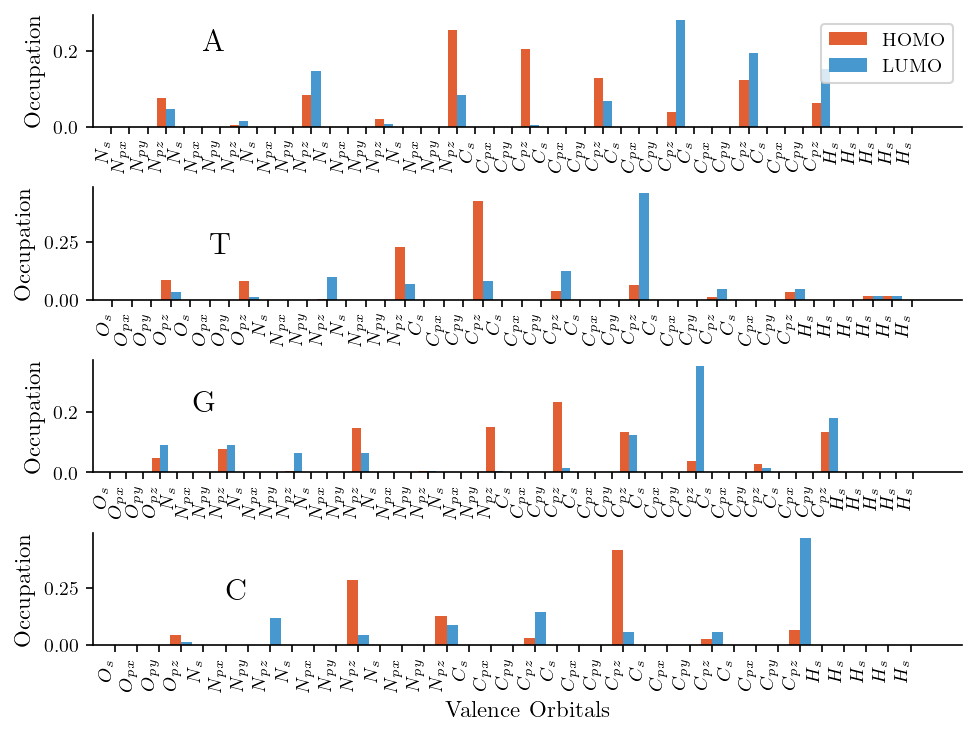
Furthermore, we illustrate the occupation probabilities of the atomic orbitals for both the HOMO and LUMO. We find that pz orbitals dominate the electronic structure of both the HOMO and LUMO. This observation aligns with the expected electronic properties of nucleobases, where pi-bonding and delocalized electron systems primarily arise from pz orbital overlap.
[8]:
mono_dict = {}
for filename in ['A', 'T', 'G', 'C']:
filepath = os.path.join(DATA_DIR, "my_geometries", "Pubchem", f"{filename}.xyz")
mono_dict[filename] = Monomer([filepath])
mono1, mono2 = mono_dict['A'], mono_dict['T']
t_EXC = calc_dipolar_coupling(mono1, mono2)
lcao_param = load_lcao_param('MSF')
H_inter = calc_H_inter(lcao_param, mono1, mono2)
t_HOMO = mono1.HOMO @ H_inter @ mono2.HOMO
t_LUMO = mono1.LUMO @ H_inter @ mono2.LUMO
print("TB parameters")
print(f"E_HOMO_A: {mono1.E_HOMO}", f"E_LUMO_A: {mono1.E_LUMO}")
print(f"E_HOMO_B: {mono2.E_HOMO}", f"E_LUMO_B: {mono2.E_LUMO}")
print(f"t_HOMO: {t_HOMO}", f"t_LUMO: {t_LUMO}", f"t_EXC: {t_EXC}")
TB parameters
E_HOMO_A: -8.4407322055674 E_LUMO_A: -4.353816583266127
E_HOMO_B: -9.090176569811193 E_LUMO_B: -4.269864330116984
t_HOMO: 0.6026700721388009 t_LUMO: -1.2373368159162437 t_EXC: 5.386221507600993
[9]:
print("Dipole Moments")
print("-------------------------------")
for filename, mono in mono_dict.items():
print(f"Base {filename}")
print(f"E_HOMO: {mono.dipole_moment}")
print(f"E_LUMO: {mono.dipole_moment}")
print("-----------------------")
Dipole Moments
-------------------------------
Base A
E_HOMO: [-1.38861688e-21 6.80150243e-21 1.29720970e-24]
E_LUMO: [-1.38861688e-21 6.80150243e-21 1.29720970e-24]
-----------------------
Base T
E_HOMO: [3.43998979e-20 5.71389727e-20 9.81324723e-25]
E_LUMO: [3.43998979e-20 5.71389727e-20 9.81324723e-25]
-----------------------
Base G
E_HOMO: [ 7.75630445e-20 -3.90737241e-21 9.59633023e-25]
E_LUMO: [ 7.75630445e-20 -3.90737241e-21 9.59633023e-25]
-----------------------
Base C
E_HOMO: [3.45158157e-20 6.64986768e-20 8.28890493e-25]
E_LUMO: [3.45158157e-20 6.64986768e-20 8.28890493e-25]
-----------------------
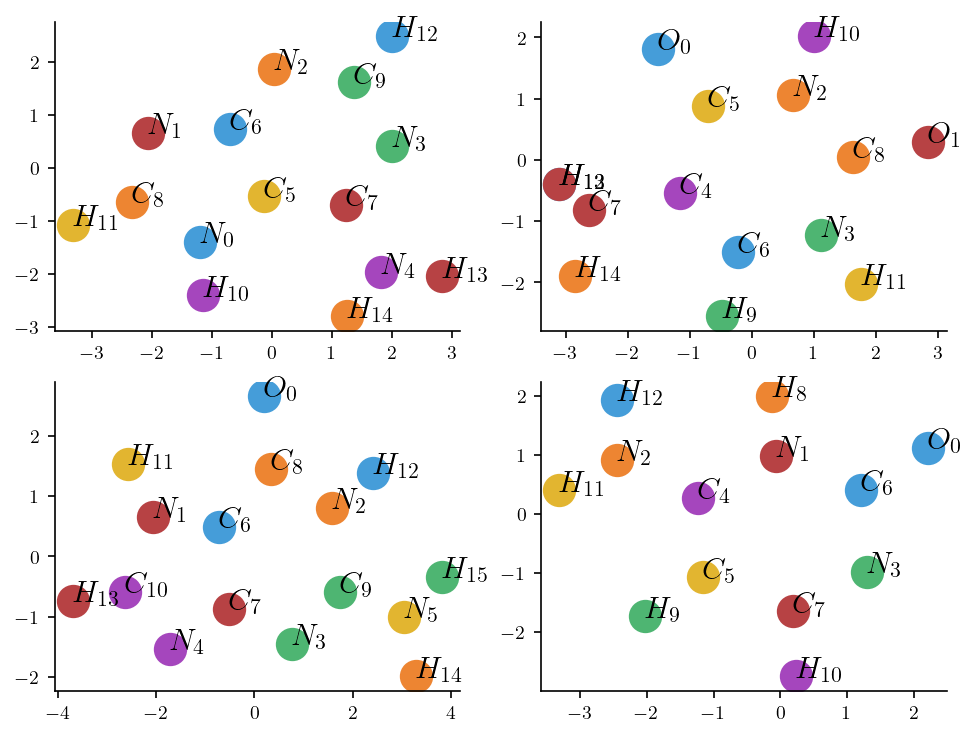
[10]:
fig, ax = plt.subplots(2, 2, figsize=(6.4, 4.8))
axes = ax.flatten()
for i, (filename, mono) in enumerate(mono_dict.items()):
atom_identifiers = []
for atom_identifier in mono.atoms_id:
atom, number = atom_identifier.split('_')
atom_identifiers.append( f'${atom}_{{{number}}}$' )
for j, atom_identifier in enumerate(atom_identifiers):
axes[i].plot( mono.atoms_coordinates[j][0], mono.atoms_coordinates[j][1], '.', markersize=30)
axes[i].text( mono.atoms_coordinates[j][0], mono.atoms_coordinates[j][1], f'{atom_identifier}', fontsize =15)
if save:
fig_filename = input("Filename for Saving: ")
plt.savefig(os.path.join(SAVE_DIR, fig_filename + '.pdf'))
[11]:
bar_width = 0.5
fig, ax = plt.subplots(4, 1, figsize=(6.4, 4.8))
for i, (filename, mono) in enumerate(mono_dict.items()):
x = np.arange(mono.num_orbitals)
ax[i].bar(x - bar_width/2, np.abs(mono.HOMO)**2, width=bar_width, label='HOMO', color='#e25f33')
ax[i].bar(x + bar_width/2, np.abs(mono.LUMO)**2, width=bar_width, label='LUMO', color='#4798ce')
orbital_identifiers = []
for orbital_identifier in mono.orbitals:
atom, orbital = orbital_identifier.split('_')
orbital_identifiers.append( f'${atom}_{{ {orbital} }}$' )
ax[i].set_xticks(x)
ax[i].set_xticklabels(orbital_identifiers, rotation=90, ha='right')
ax[i].text(5, 0.2, filename, fontsize=15)
ax[i].set_ylabel("Occupation")
ax[i].set_xlim(-1)
ax[3].set_xlabel("Valence Orbitals")
ax[0].legend()
print(f"HOMO type: {mono.get_MO_type(mono.HOMO)[0]}")
print(f"LUMO type: {mono.get_MO_type(mono.LUMO)[0]}")
if save:
fig_filename = input("Filename for Saving: ")
plt.savefig(os.path.join(SAVE_DIR, fig_filename + '.pdf'))
HOMO type: pi
LUMO type: pi
[ ]: